什么是预测模型
机器学习是一门关于数据学习的科学技术,它能帮助机器从现有的复杂数据中学习规律,以预测未来的行为结果和趋势。Sugar BI作为对数据进行分析的可视化平台,也支持用户对自己的数据使用机器学习算法进行探索试分析和趋势预测。预测模型主要包含两种,一种是内置模型,包含一些常用的分类算法和回归算法。一种是训练模型,用户可以使用机器学习平台选择更丰富的算法来训练模型并在数据模型中的预测模型中使用。内置模型在 SaaS 高级版和多账号版本(非 2 账号版本)的私有部署中支持。训练模型在开启智能预测功能的私有部署中支持。
需要注意的是为保证数据模型的计算性能,单个数据模型只能添加 3 个预测模型!
内置模型
内置模型提供了两大类算法,分类和回归。分类包括:K-MEANS,DBSCAN。回归包括:线性回归,指数(e)回归,对数(ln)回归,幂函数回归,多项式回归,决策树回归。
分类算法
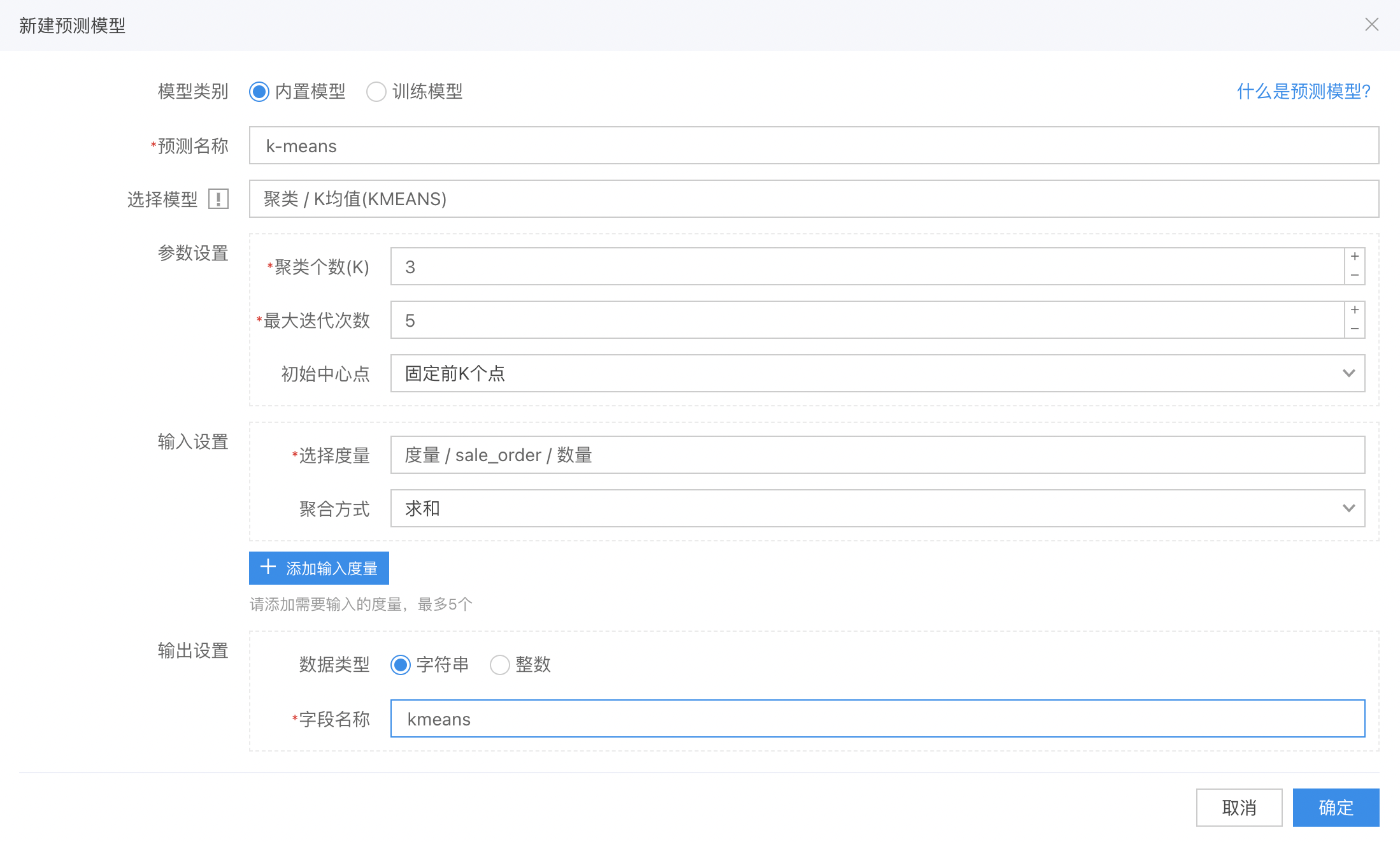
以K-MEANS 为例,配置如下:
-
配置参数
聚类个数: 将数据分为几类,最少为 2。
最大迭代次数: 将数据迭代运算多少次,为保证性能最多为 10。
初始中心点: 初始中心点的选择方式,包括固定前 K 个点、固定后 K 个点、kmeans++算法计算、随机选择。
-
输入设置中选择要进行计算的度量,最多可以选择五个。
-
最后设置输出的维度信息即可。
回归算法
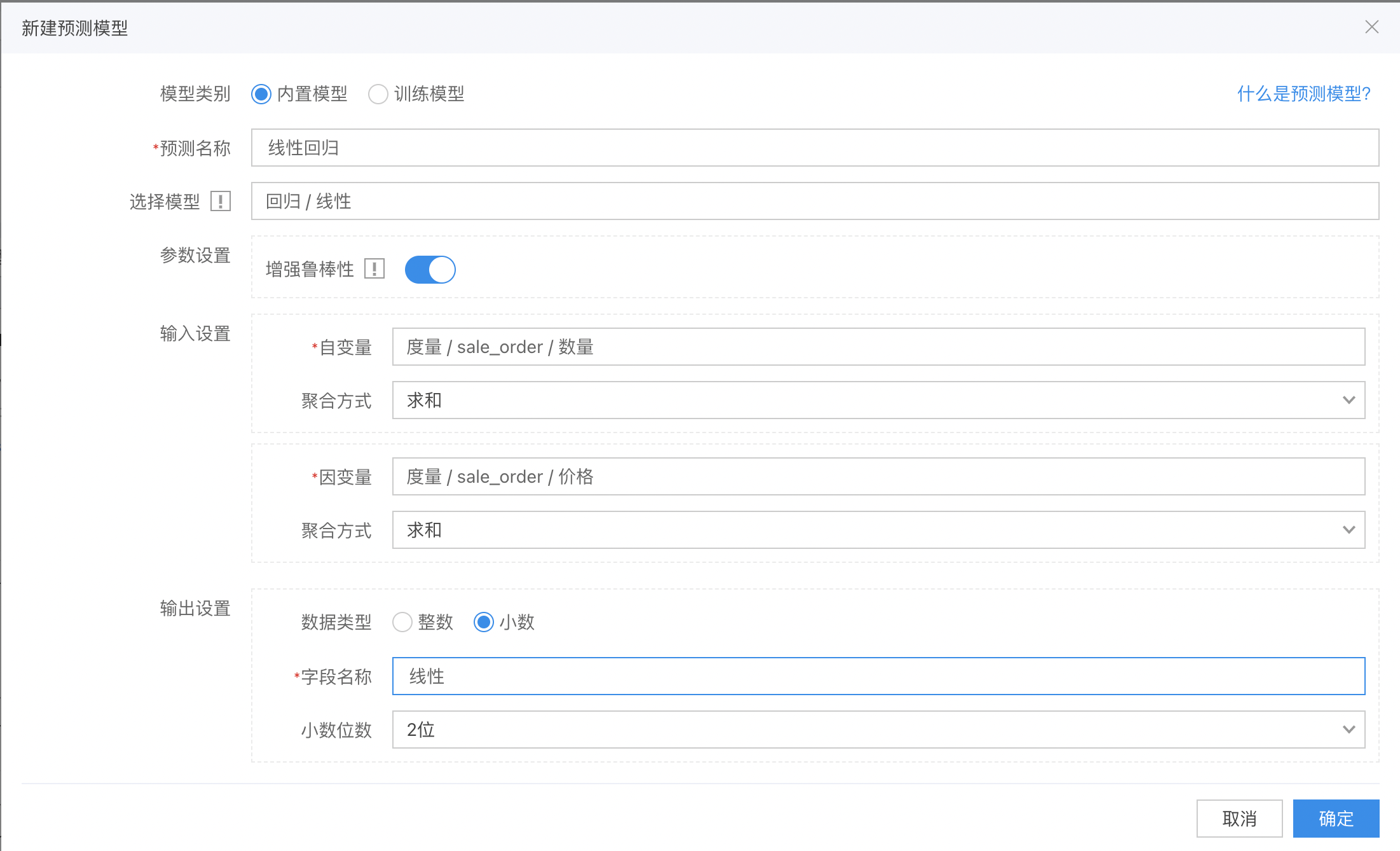
以线性回归为例,配置如下:
-
配置参数
增强鲁棒性: 提升算法的稳定性,
但会存在数据是奇异矩阵(matrix is singular)的情况,这种情况下,需要关闭该参数。 -
输入设置中设置函数的自变量和因变量。
-
最后设置输出的度量信息即可。
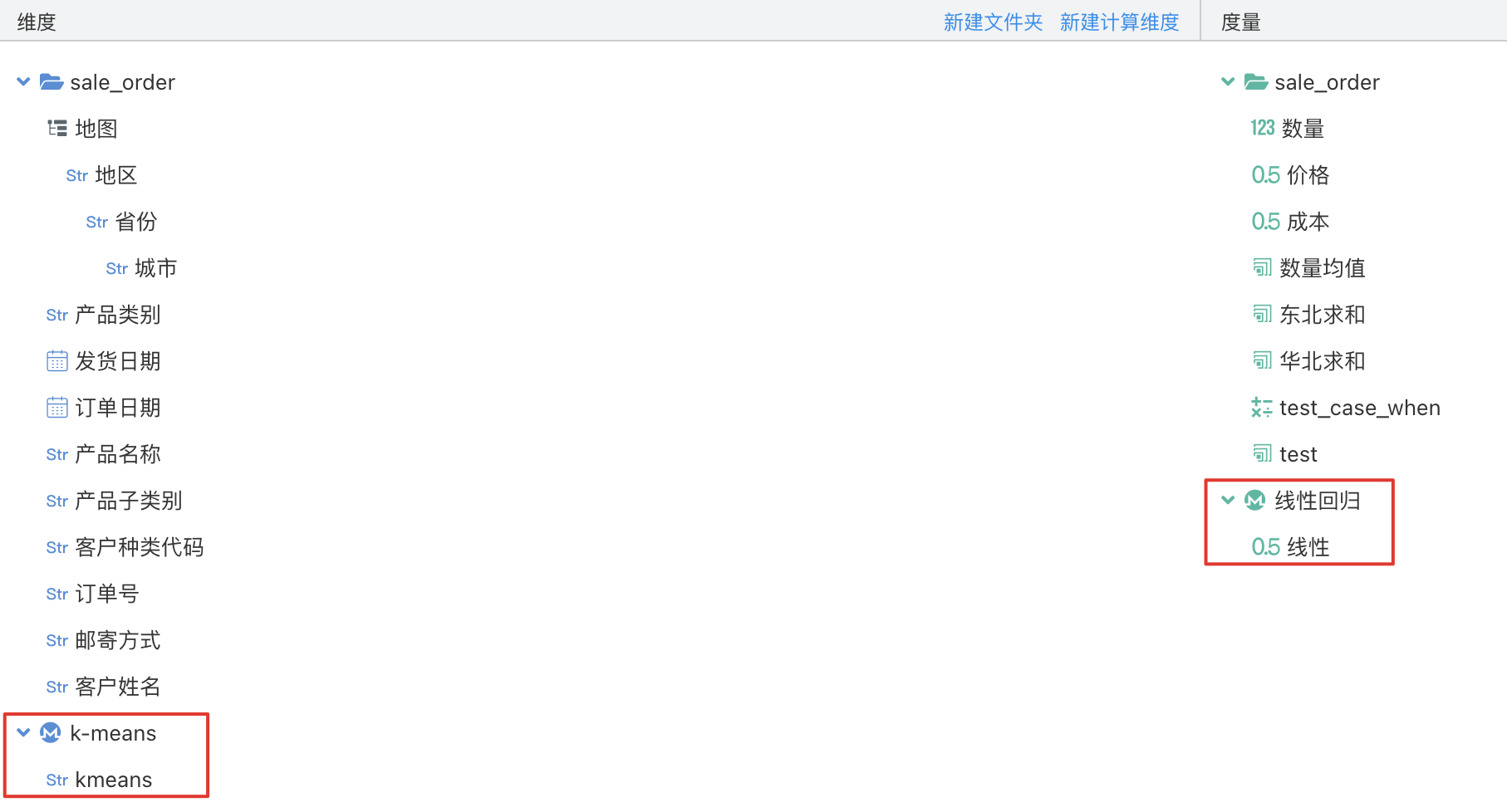
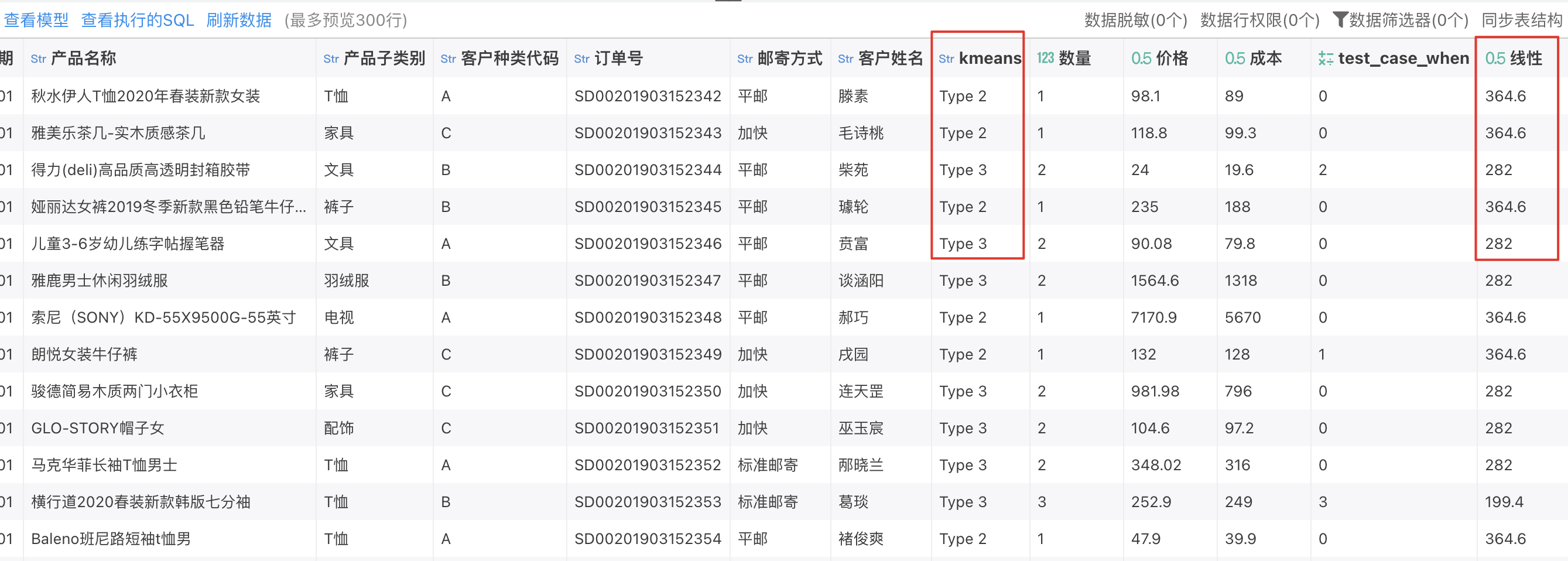
设置完成后可以看到数据模型中相应的配置,带有 M(machine learning) 标志的表示该字段是预测模型生成的字段。在相应的文件夹上右键可以新增、修改、删除预测模型。
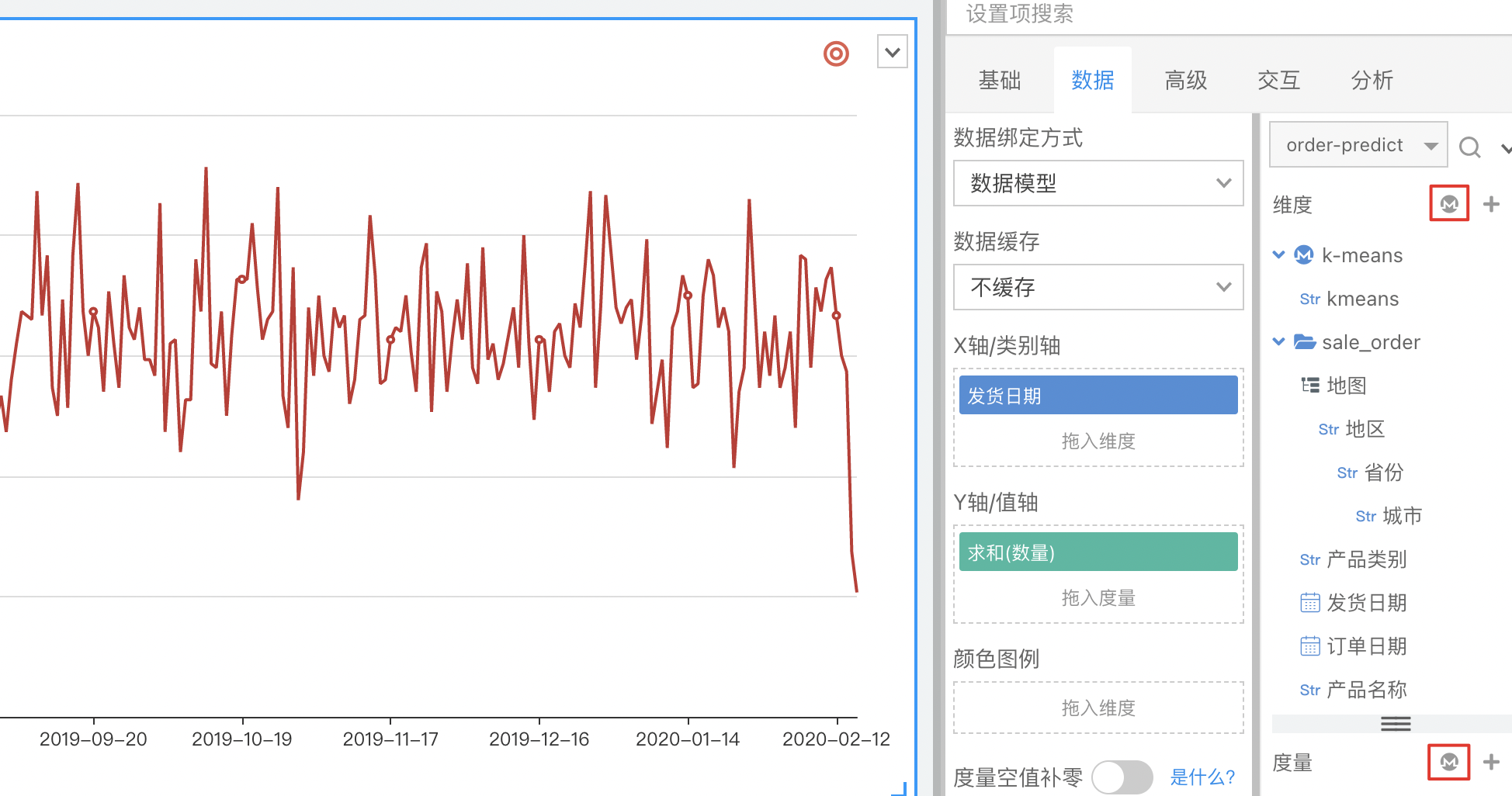
点击查看数据,即可看到数据的预测结果。
训练模型
训练模型在开启智能预测功能的私有部署中支持,需要购买包含智能预测功能的 License。
预测模型在图表中使用
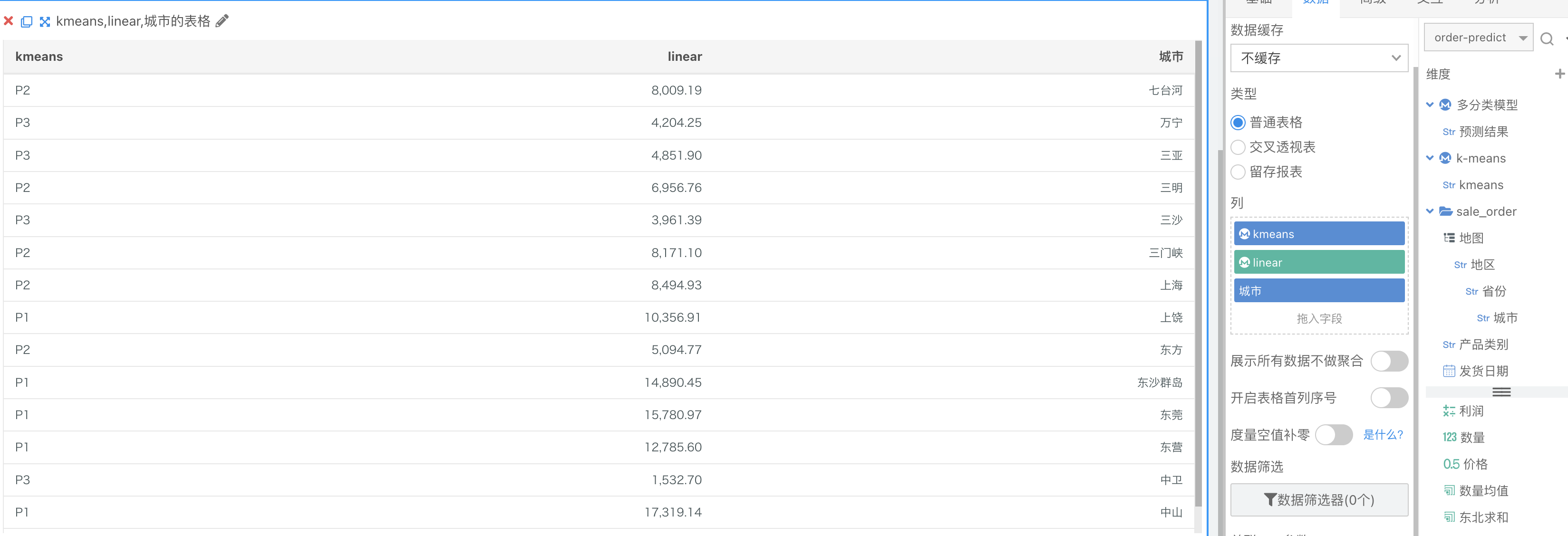
预测字段在图表中使用和其他字段一样,直接拖入即可。
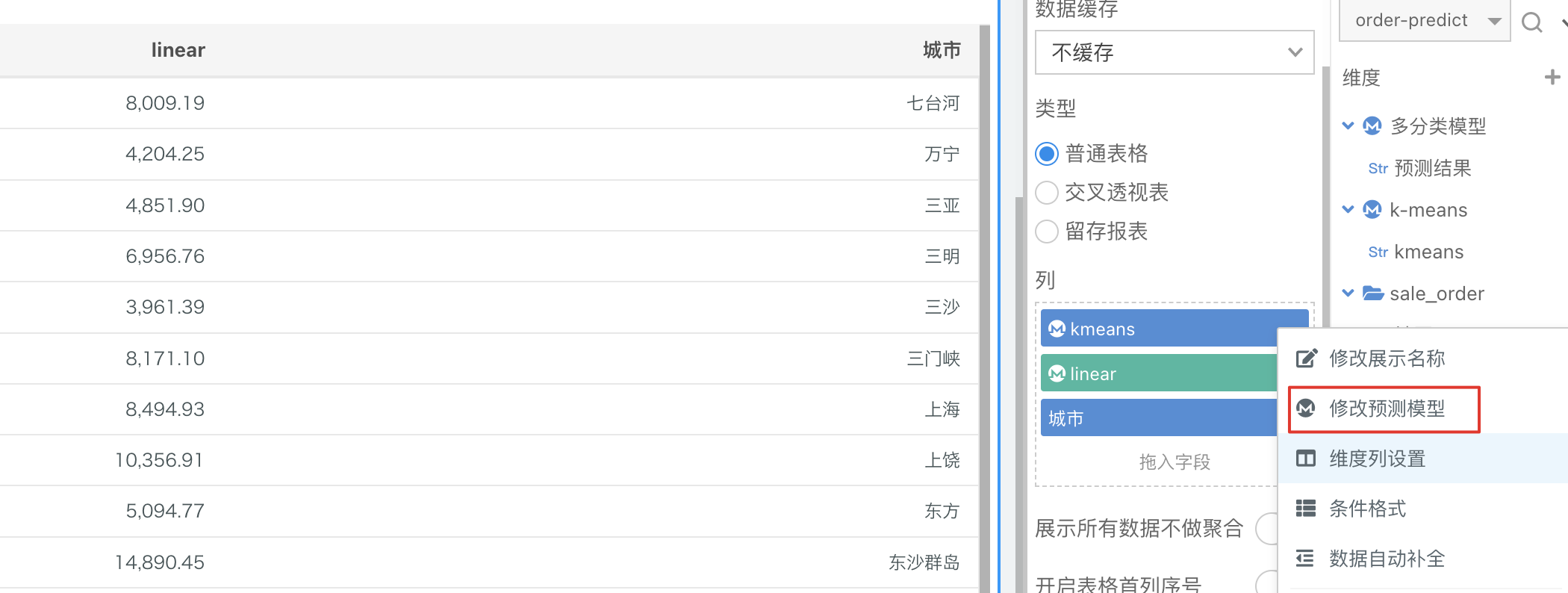
对于内置模型,如果需要对算法的参数进行快速的调整,可以直接在字段上右键「修改预测模型」。需要注意的是,算法的切换只能同类型进行切换,例如:K-MEANS 切换为 DBSCAN。
对于报表和大屏,也可以像计算字段一样,建立页面级别的预测字段。该功能的开放条件与数据模型中使用预测模型的开放条件一致。